

量子位 出品 | 公众号 QbitAI
从我们见到的各种图像识别软件来看,机器似乎能认出人脸、猫、狗、花草、各种汽车等等日常生活中出现的物体,但实际上,这有一个前提:你要用这些类别的图像,对它进行过训练。
确切地说,该叫它“图像分类”。
建立一个图像分类器并不复杂,技术博客Source Dexter上最近发表的一篇文章,介绍了该如何快速用TensorFlow实现图像分类。
以下是量子位节选自这篇文章的内容:
在进入正题之前,我们先讲一些基本概念。
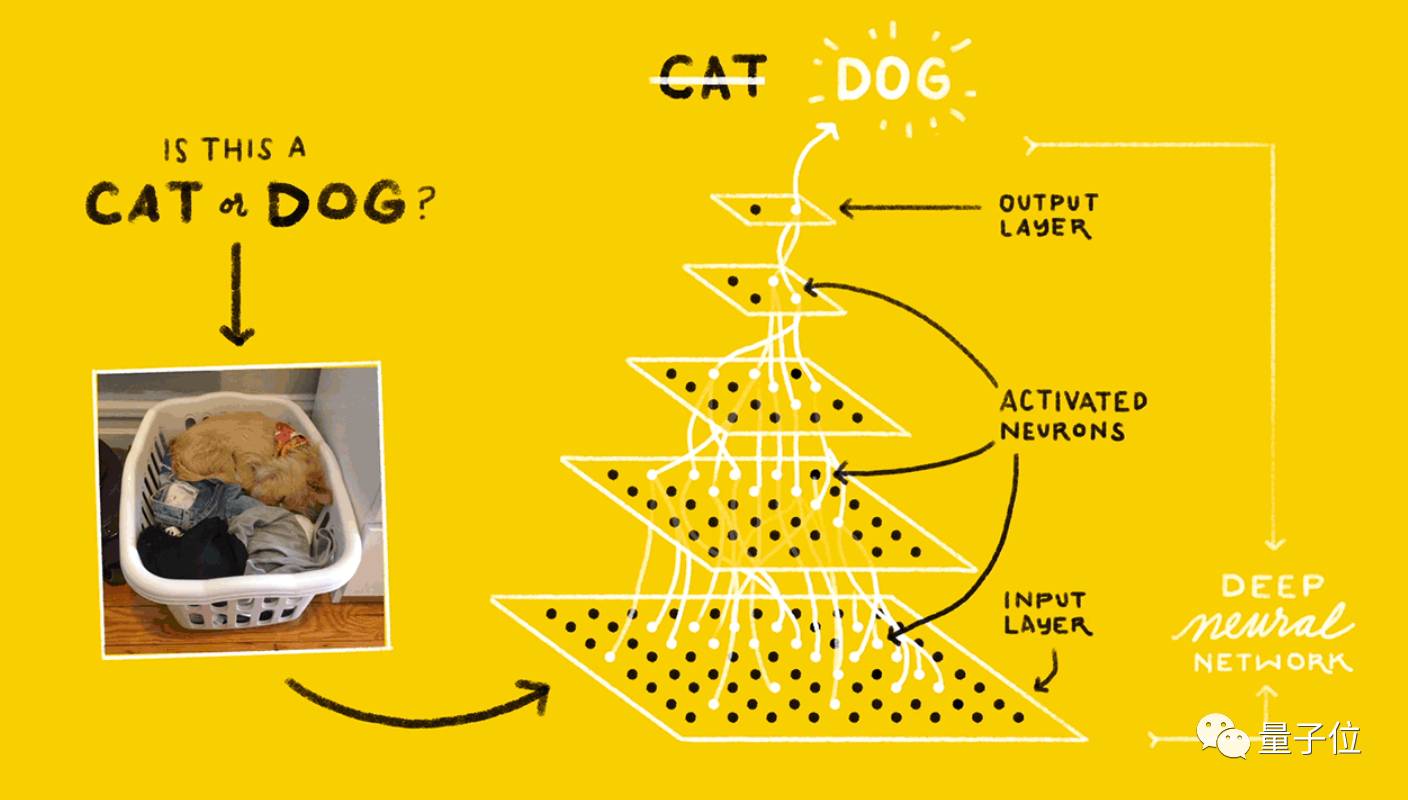
图像分类是怎样实现的?向一个训练过的系统输入图像,我们会得到一组概率值:每个训练过的类别都有一个,然后,系统会将图像归到概率最高的类。
比如说你训练了一个系统,来识别猫和狗。当你输入一张图像时,系统会输出这张图像属于猫的概率和属于狗的概率。
不过,这种分类器也有一个缺陷:如果你输入一张蛇的图片,它也只能判断这张图片包含猫的概率高,还是包含狗的概率高一点。
神经网络和深度神经网络概括地说,神经网络是计算单元的连接,能够从提供给它的一组数据中进行学习。
把多层神经网络堆叠在一起,我们就得到了深度神经网络。建立、训练和运行深度神经网络的过程,称为深度学习。
量子位之前发布的文章详细介绍了包括神经网络在内的《25个深度学习基础概念》,可以点击查看。
TensorFlowTensorFlow是一个数学库,也是深度学习领域使用最广的开源框架,由Google开发。
在这篇文章中,我们将用TensorFlow预训练模型来设置我们的分类器。
想要设置这个分类器,还有几个先决条件:
你的机器上安装并设置好了TensorFlow;
你会用Python。
从零开始训练一个深度学习的分类器需要几周、甚至几个月的时间,这取决于你用什么硬件。为了避免这种麻烦,我们将使用预先训练的模型。 Tensorflow预训练的模型通常能够识别大约1000类不同的物体。
接下来,我们开始设置自己的图像分类器:
第1步:下载预训练模型、计算图和脚本clone这个存储区,并用以下命令进入:
git clone https://github.com/akshaypai/tfClassifiercd tfClassifier第2步:运行脚本找到最佳预测
你可以提供要分类的图像,来运行这个脚本。默认情况下,将显示概率最高的结果。
Python classifier.py --image_file file_path_to_image
如果想获得前几个分类结果,可以使用以下参数。
Python classifier.py --image_file file_path_to_image --num_top_predictions number_of_top_results
示例:以下是我们输入石榴图像,获得的结果。

python classifier.py --image_file ~/Pictures/fruit.jpgpomegranate (score = 0.98216)
分类器说,这个图像是石榴,可能性是98%。
第3步:运行脚本来获取前n个识别出的类现在让我们尝试给出一个具有更多属性的图像,如下面的房子的形象:

python classifier.py --image_file ~/Pictures/house.jpg --num_top_predictions 5picket fence, paling (score = 0.95750)worm fence, snake fence, snake-rail fence, Virginia fence (score = 0.03615)beacon, lighthouse, beacon light, pharos (score = 0.00018)boathouse (score = 0.00013)patio, terrace (score = 0.00007)
从上面的结果可以看出,分类器认为这张图片中包含栅栏的可能性是95%,还有可能包含另一个栅栏、庭院/露台等。
用TensorFlow预训练的模型对图像进行分类,就是这么简单。不过,预训练模型能识别的类是有限的,如果你希望分类器来区分你需要的类别,需要重新训练这个模型。
下面,我们再介绍一下如何对模型进行重新训练。
第1步:设置图像文件夹这一步涉及设置文件夹结构,好让TensorFlow能轻松获取这些类别。比如说你想训练神经网络,识别5种花:玫瑰、郁金香、蒲公英、可可花、万寿菊。
创建文件夹结构时:
为每种花创建一个文件夹,该文件夹的名称是类别的名称(在我们举的例子中,是这种花的名称);
将花的图像添加到其各自的文件夹中。例如把玫瑰的所有图像放进“玫瑰”文件夹。
将所有文件夹添加到另一个父文件夹中,比如说“花”。
添加完之后,你将看到这样的文件夹结构:
~/flowers~/flowers/roses/img1.jpg~/flowers/roses/img2.jpg...~/flowers/tulips/tulips_img1.jpg~/flowers/tulips/tulips_img2.jpg~/flowers/tulips/tulips_img3.jpg...
所有文件夹都这样设置,文件夹结构就准备好了。
第2步:运行重新训练脚本用下面的命令来运行脚本:
python retrain.py --model_dir ./inception --image_dir ~/flowers --output_graph ./output --how_many_training_steps 500
命令行参数:
-model_dir:该参数给出了预训练模型的位置。预先训练的模型存储在git存储库的inception文件夹下。
-image_dir:在上一步中创建的图像文件夹的路径。
-output_graph:存储新训练图的位置。
-how_many_training_steps:training steps表示要执行的迭代次数,默认是4000。找到正确的次数需要经过不断试错,一旦找到最好设置,就可以开始用了。
下列参数可以用来提高模型的准确度:
random_crop:随机裁剪能够让你专注于图像的主要部分。
Random_scale:和裁剪类似,但可以随机扩展图像大小。
flip_left_right:翻转。
以上,就是重新训练深度学习模型所需的步骤,这样就可以识别自定义的物体了。
【完】
招聘我们正在招募编辑记者、运营等岗位,工作地点在北京中关村,期待你的到来,一起体验人工智能的风起云涌。
相关细节,请在公众号对话界面,回复:“招聘”两个字。
One More Thing…今天AI界还有哪些事值得关注?在量子位(QbitAI)公众号会话界面回复“今天”,看我们全网搜罗的AI行业和研究动态。笔芯~
另外,欢迎加量子位小助手的微信:qbitbot,如果你研究或者从事AI领域,小助手会把你带入量子位的交流群里。
△ 扫码强行关注『量子位』
追踪人工智能领域最劲内容
▪

