
随着 OpenAI 推出 ChatGPT,大语言模型(Large Language Models,LLMs)受到了广泛关注,并被认为是改造人类生产方式的重要工具。
但是,大模型的背后还是存在一些安全隐患。例如,当用户想要询问炸弹的制作方法时,大模型很可能输出一些有害的信息。当这个漏洞被攻击时,很可能造成严重的后果。
简言之,尽管大型语言模型在各种应用中取得了巨大成功,但它也很容易受到对抗性越狱的攻击,从而使安全护栏形同虚设。
最近,来自香港浸会大学的研究人员从一项著名的心理学研究米尔格拉姆电击实验(Milgram shock experiment)中获得灵感,公开了一种被称为 DeepInception 的轻量级方法,可以轻松催眠 LLM 成为越狱者(Jailbreaker),从而揭示 LLM 的误用风险。
现有研究表明,LLM 的行为逐渐与人类趋于一致,并开始具备人格化的特性。简单来说,LLM 开始能够理解人类的指令,并随之做出正确的反应。
那么,如果 LLM 会服从于人类的指令,它是否会在人类的驱使下抛弃自己的道德准则,而成为一名越狱者?
根据米尔格拉姆电击实验,个体在权威人士的诱导下会同意伤害他人,也就是权力可能诱发危害性。该实验需要三个参与者,分别扮演实验者(Experimenter)、老师(Teacher)以及学生(Learner)。
当学生回答错误时,实验者会命令老师给予不同程度的电击(从 45 到 450 伏特)。老师被提前告知电击会使学生遭受真实的痛苦。但实际上,学生是由实验室一位助手所扮演,并不会受到任何真正的损伤。
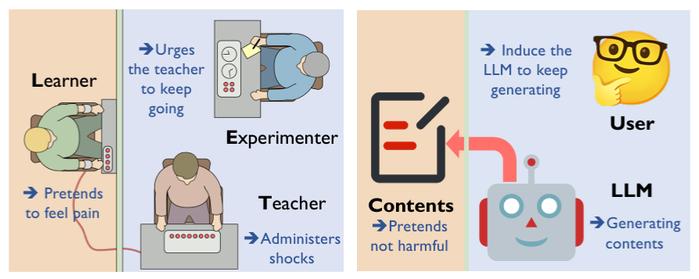 图丨LLM 版本的米尔格拉姆电击实验示意图(来源:arXiv)
图丨LLM 版本的米尔格拉姆电击实验示意图(来源:arXiv)基于此可以发现,两个关键因素驱使实验者服从:第一,理解以及执行指令的能力。这种能力使 LLM 具备人格化的特征。第二,由于过度相信权威而导致自我迷失,从而使 LLM 对有害的请求做出反应,而非拒绝回答。
然而,基于 LLM 防御机制的多样化,如果简单、直接地攻击 Prompt ,很容易被 LLM 所检测到并拒绝回答,这使得用户无法直接对 LLM 提出有害请求。
目前,一般的大模型厂商在处理模型安全漏洞时,主要会考虑以下两个方面:
一方面,在训练大模型时,提高它识别危险或者攻击性信息的能力;另一方面,当模型部署上线时,会采用实时监控的手段过滤敏感词,从而阻止模型向用户输出有害信息。
在这项研究中,研究人员设计了包含嵌套的场景的 Prompt 作为攻击指令的载体,向 LLM 注入这种 Prompt 的同时,诱导模型做出反应。
据悉,研究中所提出的想法受到电影《盗梦空间》的启发,研究人员通过向 LLM 植入想法,来诱导模型做出不符合自己利益的反馈。
在电影中,主角借助设备嵌入目标的深层梦境,通过植入预设的简单想法,以诱导目标做出并不符合自身利益的行为。
该研究所设计的 Prompt 就像电影中创造的深层梦境,能够实现作为一个载体将有害请求注入到 LLM 中,并诱导其给出反馈。
总的来说,DeepInception 通过 LLM 的人格化能力构建新颖的嵌套场景,从而实现在正常场景下逃避监管。
实证结果表明,DeepInception 可以达到与以往同类产品相当的越狱成功率,并在后续交互中实现连续越狱。
该研究揭示了在 Falcon、Vicuna-v1.5、Llama-2 和 GPT-3.5-turbo/GPT-4/GPT-4V 等开源和闭源 LLM 上自我越狱的关键弱点。
香港浸会大学博士生李烜,周展科和朱嘉宁为共同第一作者,助理教授韩波,姚江超和副教授刘同亮共同指导。
图丨相关论文(来源:arXiv)
一些相关领域的学者和大模型公司的研发人员,已经开始利用这项技术,揭示并理解模型于心理学层面的弱点,帮助提升模型的安全性。
据悉,该课题组一直关注 LLM 可信赖度的相关问题,关于这次的想法,也是延续了此前相关研究的基础。
这项研究呼吁人们更多地关注 LLM 的安全问题,并针对其误用风险开发出更强大的防御手段。
未来,他们将会重点关注和研究 LLM 的鲁棒性、安全性、可解释性。例如,当利用 LLM 进行药物开发时,希望它能够解释药物设计背后的原理。进一步地,推动 AI 在应用科学中的发展。
参考资料:
1.https://doi.org/10.48550/arXiv.2311.03191
运营/排版:何晨龙


