
论文链接:https://arxiv.org/abs/2105.15078
[ 导读]本文主要介绍清华大学胡事民团队最新发表在Arxiv上的研究论文,主要针对注意力可以使得MLP架构追赶甚至替代CNN吗?以及未来又有哪些研究方向可以做呢?这两个问题给出了一些回答和展望。
在2021年5月份,谷歌,清华大学,牛津大学,Facebook等四大著名研究机构都不约而同的分享了它们的最新成果,它们都提出了一种新的学习架构,主要由线性层组成,声称它们基本可以比拟甚至优于CNN模型。这在学术界和工业界立即引发了关于 MLP 是否足够的讨论和辩论,许多人认为学习架构正在回归 MLP。这是真的吗?
因此,本文从这个角度出发,我们将简要介绍了网络架构的历史,包括多层感知器(MLP)、卷积神经网络(CNN)和Transformer。最后我们将详细比较最新提出来的MLP架构之间的区别与共性。然后就目前MLP网络架构面临的挑战,提出了一些新的视角和方向,希望能激发大家后面的研究。
简介:多层感知器(MLP)主要由输入层和输出层组成,中间可能有多个隐藏层。每层之间通常利用线性变换和激活函数进行完全连接。在深度卷积神经网络(DCNN)兴起之前,MLP 是神经网络的基础,极大地提高了计算机处理分类和回归问题的能力。然而,由于MLP拥有大量参数,计算成本高且容易过度拟合,而且因为层之间的线性变换总是将前一层的输出作为一个整体,所以MLP在捕获输入特征图中的局部特征结构的能力较弱。但是,因为当时的计算机算力和性能比较有限,无法获得大量的数据进行训练。所以,MLP 的功能在提出时并没有得到充分探索。
之后,随着LeNet的提出,利用五层卷积神经网络大大提高了手写数字识别的准确性。后来,AlexNet的提出使得CNN得到了广泛的认可:它比LeNet模型更大,并在ImageNet2012大型视觉识别挑战赛中在以显著的优势击败所有其他竞争对手。从此时起,开发了具有更深层次架构的模型便成为了主流,其中许多优化的模型在许多领域已经取得了比人类更准确的效果,继而CNN在科学研究、工程和商业应用中产生了深刻的范式变化。然而,撇开计算能力和训练数据量方面的进步,CNN的成功关键在于它们引入的inductive bias (归纳偏差)即:它们假定信息具有空间局域性,因此可以利用具有共享权值的滑动卷积核来减少网络参数的数量。然而,这种方法的副作用是,降低了CNN的receptive fields(感受野),从而就降低了CNN学习长期依赖的能力。为了扩大感受野,就需要使用更大的卷积核,或者必须使用其他特殊策略,如dilated convolutions。
最近,在自然语言处理方面提出的Transformer结构取得了巨大成功,最近它又在视觉任务上取得了较大的效果。而注意力机制又是Transformer的核心,它能够很容易地以注意力特征图的形式学习输入数据中任意两个位置之间的长期依赖关系。然而,这种额外的自由度和减少的inductive bias意味着有效地训练基于transformer的架构需要大量的数据。因此,为了获得最好的结果,这些模型应该首先需要在一个非常大的数据集上进行预训练,比如GPT-3和ViT。
为了避免上述学习体系结构的缺点,并以更低的计算成本获得更好的结果,最近,四种基于MLP的网络结构几乎同时被提出。它们的共同目标是充分利用线性层来提取特征信息。我们在下面将主要总结这些架构;这四种方法都采用了transposition的方法来实现所有尺度上的交互,然后也使用了残差连接和正则化的方法来确保训练的稳定性。
每个网络结构的主要区别
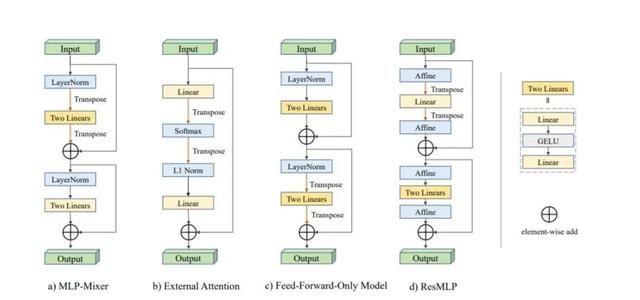
MLP-Mixer
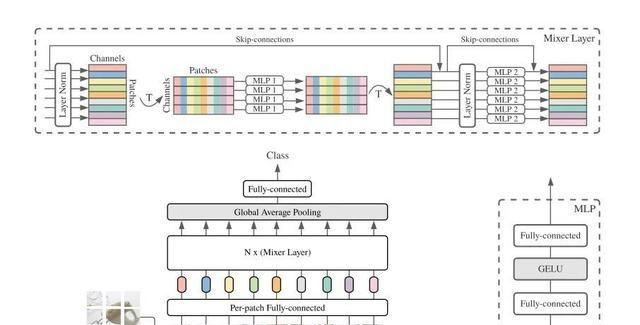
MLP-Mixer首先将个分辨率为不重叠的image patches,作为输入,每个patch首先通过一个共享权重的线性层投射到一个c维嵌入空间:因此,输入图像的表示是一个矩阵,。接下来,X被送入一系列相同的mixer layers,每个mixer layer 由一个token-mixing MLP块和一个channel-mixing MLP块组成,分别混合来自所有patch和所有通道的信息。我们可以将计算表示为:
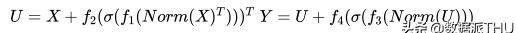
其中、···、为线性层,为GELU(非线性)激活函数。采用layer mormalization。代表每次通道特征聚合后的中间矩阵:x中列向量的共享权重映射。同样,每个patch进行两次线性变换,得到输出。
External Attention
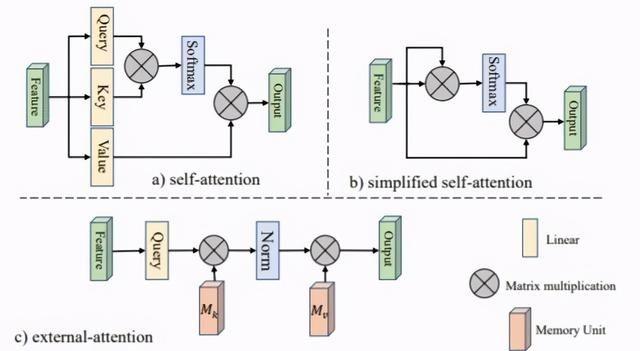
External Attention揭示了自我注意力与线性层的关系。首先将自注意力简化为如下方程,其中代表输入特征图。
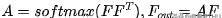
然后引入外部存储单元,将M-to-M注意替换为M-to-M注意,如下所示:
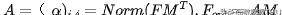
最后,像self-attention一样,它使用两种不同的记忆单元和作为key和value来增强网络的能力。外部注意的总体计算如下:
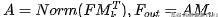
又因为是矩阵相乘,它在中是线性的,因此又可以写作:
最后的输出可以表示为:
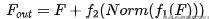
基于external attention,Guo等人还设计了一个multi-head external attention ,实现了一个名为EAMLP的全MLP体系结构。
Feed-forward-only Model
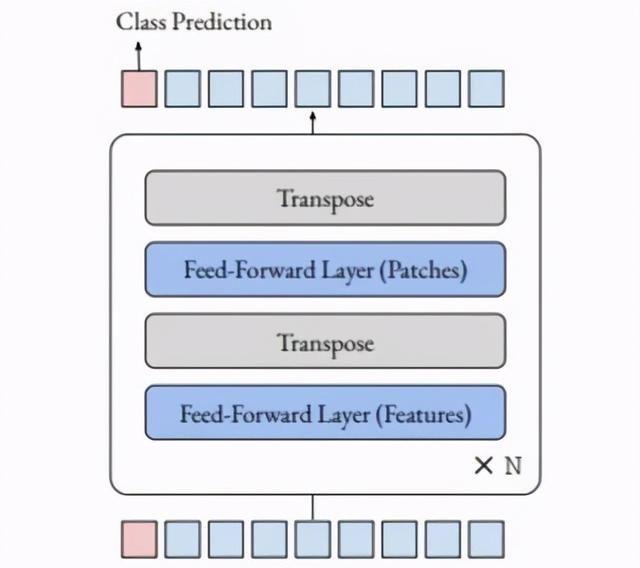
Feed-forward-only Model将Transformer中的注意力层替换为token维度上的简单前向反馈层。它首先在通道维度上使用线性层,然后在一个线性块的token维度上使用线性层。给定输入,详细计算可表示为:
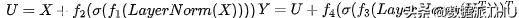
ResMLP

ResMLP也分别以per-patch和per-channel的方式来对信息进行聚合,具体可以表述为:
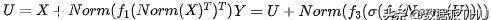
ResMLP的一个主要区别是,它在规范化层的角色中使用仿射转换。这个仿射变换由两个可学习的参数向量,他们可以对输入的组成进行缩放和移动:
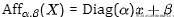
请注意,上面没有使用输入的统计信息,因此可以在推理期间将其集成到线性层中以提高速度。
MLP结构的共性
Long distance interactions
跟Self-attention一样,这四种方法考虑了不同patch之间的交互作用。MLPMixer、ResMLP和基于仅使用前向反馈的模型,都是使用线性层作用于Token 维度上,从而来实现以允许不同的patch之间的信息交互。External attention采用softmax和L1归一化来发挥类似的作用。与神经网络不同的是,这些模型主要考虑patch之间的长距离交互,从而来自动选择合适的和不规则的感受野大小。
Local semantic information
与自然语言中的独立单词不同,单个像素只有很少的语义信息,它们与其他像素的交互不能直接提供信息。因此,在使用mlp之前,我们需要提取有意义的语义信息。MLP-Mixer、ResMLP和forward - only模型将图像分割成16×16个局部patch来获取语义信息。External attention采用T2T模块或CNN骨干,在将信息传递到线性层之前提供丰富的语义信息。
Residual connections
残差连接解决了梯度消失的问题,可以使训练过程相对稳定,因此它们通常用于深度卷积神经网络。它们还有利于基于线性层的体系结构构造,因此被上述所有模型所采用。
Reduced inductive bias
神经网络的局部化处理会导致归纳偏差,当训练数据足够多时,会降低准确率。最近引入的MLP体系结构在单个token上独立使用线性层,或一起同等的地处理所有token,从而可以降低归纳偏差。
一些挑战和新的方向
这些新引入的体系结构具有简单的网络结构和快速的推理吞吐量。然而,在ImageNet上,他们的结果目前比最好的cnn或Transformer网络提供的结果低5-10%。在准确性和速度之间的权衡上,它们也没有明显优于轻量级网络。因此,如果要实现这种结构的潜力,还需要更多的研究。
所有的线性层都采用一种直接或间接地方式来处理图像patch,提取局部特征,从而降低计算代价。将图像分割成不重叠的patches再次引入归纳偏差。一方面,CNN能很好地捕捉局部结构,但缺乏处理远距离交互作用的能力。另一方面,这四个体系结构提供了一种处理远程交互的好方法,因此我们可以很自然的将两种架构的优点结合起来。
这四种方法的主要目的之一是避免使用self-attention。但我们却可以将Transformer的一些有效配置应用到这些线性体系结构。例如,Transformer可以使用多头注意力,那么基于MLP的网络结构同样也可以使用类似的多头机制来提高模型的能力。
残差连接在所有这些方法中都起着关键作用,这表明网络结构至关重要。因为这些新架构比CNN简单,所以需要更好的主干(因此,我们可以设计更好地主干网络模型)。
由于这些新架构的简单性,它们可以轻松处理不规则的数据结构,包括点云、图表等,在各种应用中使用。此外,这种灵活性保证了建立跨模态处理的模型的能力,并为所有模式的数据提供一个通用的网络主干。
MLP机制一个额外的好处是,所有的计算都是矩阵乘法,可以在深度学习框架中高度优化,并易于执行硬件。这种简单性可以促进工业和商业的部署,也可以减少资源消耗。
总结
总的来说,新的体系结构分别在element(token)维度和通道维度上应用线性层来学习和实现特征矩阵中任意两个位置之间的远程交互,而传统的MLPs将这两个维度混合在一起作为一个长向量,从而使得他们之间的有效交互学习变得更加自由。我们的结论是,新的体系结构不应当是简单地重用传统mlp,而是对传统mlp的重大改进。
编辑:黄继彦


